This or That is one of those projects that I think has a lot of potential and still tinker with today. The core flow of the application is digesting user input and displaying aggregated results. If you’ll follow, I’ll take you over some challenges and neat aspects of the application.
What is it?
This or That pits two random things against each other - think Batman versus Tacos or Dodo Bird versus Casette Tapes. Every day, a new competition is formed with a sprinkle of sophisticated randomness. Users are then tasked with providing their vote on which they think is better.
How to avoid images
For each competitor, it made sense that they would have a corresponding image - web apps shouldn’t just be text and this would give users something to look at. Sounds like a simple enough ask but turns out it can get a little complicated quickly. I found myself needing to answer questions like; where to store them, how they should be rendered, how to source them, etc. Would it be that hard? From a storage perspective, maybe not; we could save them in an S3 bucket or something but that is extra work and also not free. Storage aside, sourcing was going to be the biggest pain point. I was not sure if I had to worry about copyright issues and finding images of a similar aspect ratio and size let alone doing that for 100s of competitors - what a nightmare. Surely, there is a better way?
—enter gifs—
Behold, my silver bullet to dealing with images, the GIF! GIPHY has a pretty solid API to search and load gifs which made it relatively easy. The main benefits of using gifs is that I don’t need to worry about copyrights, aspect ratios (as much), and frankly they are more fun than static images - look at that velociraptor!
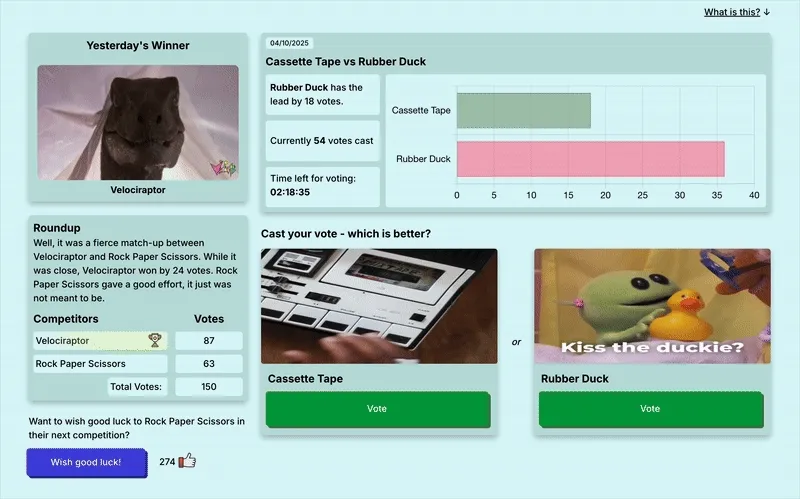
The first approach I took was to use the API to query for a gif based on the competitors name and render whatever giphy decided to provide. While this worked, it was not ideal as I was getting some pretty random gifs and without much quality control. I also did not love the fact that different users would see different gifs for the same competitor - it’s inconsistent and weird. The solution that I arrived at was to save the gifs ID to the competitor so that could be used in my query and the gif would be consistent for all users. This was a much better experience!
All is well then?
Not entirely. The GIPHY API is solid but like most free APIs, there are limitations. At the time of writing, the limit is ~100 queries/hr which is not a lot. Of course, I don’t really expect to ever have a lot of users but I was worried nontheless about hitting that limitation and being out luck. Unless you have solid reason, it is not very good practice to make multiple requests for the same infomation more than once in a session. So, let’s use session storage for a lite caching system.
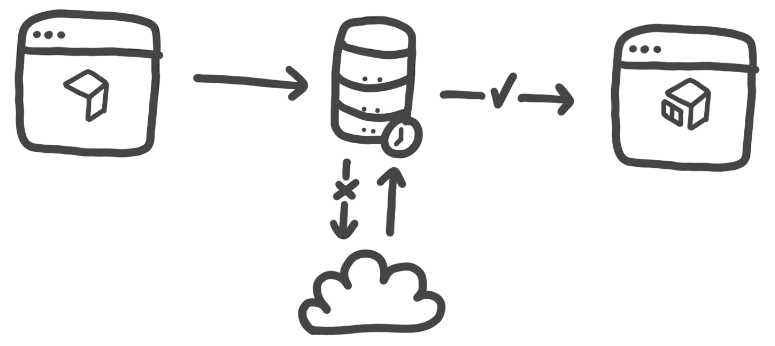
We first check if a gif with the ID exists in the browsers storage, if it does, we use that. If it doesn’t exist, we make the request to GIPHY and save the gif data to session storage. This way, we are not making unnecessary requests to GIPHY and reducing the likelihood of nearing the rate limit.
You can read more about GIF handling here .
Smart Reconciliation
What is smart reconciliation?
It is a fancy way of saying an automated process of determining competition results and creating new ones. Every 24 hours, a cron job runs on my server that closes out the current competiton, determines the winner, and then creates a new randomized match-up of competitors.
From a high-level, it looks something like this:
import cron from 'node-cron';
async function rotateDailyCompetition() {
await reconcileCurrentCompetition();
createNewCompetition();
}
cron.schedule("0 0 * * *", () => rotateDailyCompetition());
There are a few areas that contribute to the smart side of reconciliation. One area that directs some of the controlled randomness is in createNewCompetition. We have logic built to make sure that there is randomness in the compeititors chosen i.e. the same competitors are not always pitted against each other. To help achieve this, I utilize MongoDB’s Aggregation Pipeline . Aggregations are a powerful method that allow you to chain multiple operations where the output of one operation is the input to the next.
My aggregation looks something like this where recentIds is an array of the last 10 competitors that have been in the past 5 competitions.
Competitor.aggregate([
{ $match: { _id: { $nin: recentIds } } },
{ $sample: { size: 2 } },
]);What’s next
There are some areas of this application that I still have plans for.
From a code and technology standpoint, I would like to convert the frontend to TypeScript. Moving to TypeScript would allow me to code more safely and in the long run, foster a healthier codebase. I am also like considering a migration away from Next.js - I do not think the app takes advantage of enough of the framework to justify using it, I’d likely stick with React just to limit the amount of rewrites.
From a feature perspective, I would like to add a leaderboard that shows the most popular competitors. I think this would be a fun way to show off some of the data that is being collected. I’d also like to add a subscribe option so user’s can have the option to receive email notifications when new competitions are available - could be good for engagement. Finally, some light gameification would be neat - users could earn streaks and badges for voting on competitions.